복잡하게 얽힌 관계망 속에서 '가장 친한 그룹'만 골라내는 알고리즘이 나왔다. 방대한 마케팅 데이터에서 특정 고객군을 분석하거나 이상 거래 내역을 탐지할 때 활용할 수 있을 것으로 보인다.
UNIST(울산과학기술원)는 김정훈 컴퓨터공학과 연구팀이 의미 있는 집단만 찾아내는 새로운 '커뮤니티 탐색' 기법을 개발했다고 28일 밝혔다. 연구 결과는 31일부터 내달 5일까지 인도 벵갈루루에서 열리는 '2026 SIGMOD'에 채택돼 발표한다. SIGMOD는 데이터베이스 분야 최고 권위 학회 중 하나다.
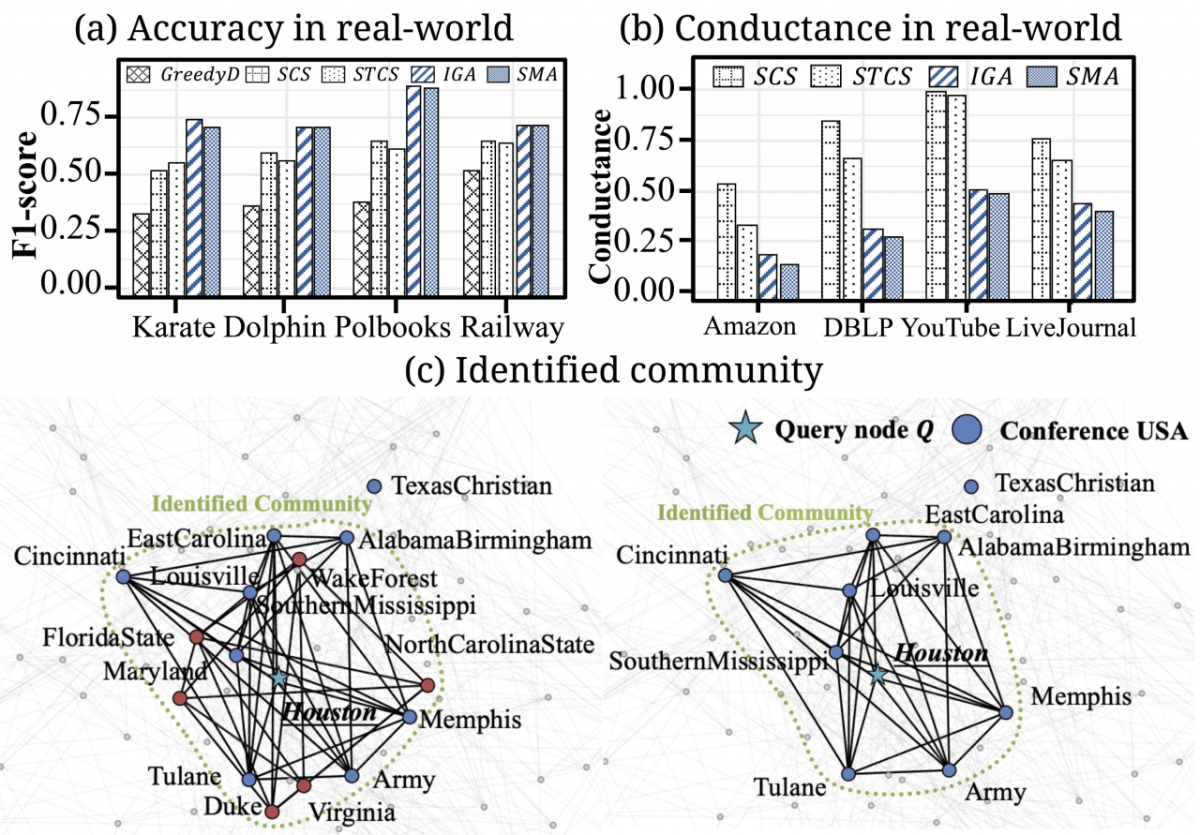
커뮤니티 탐색은 방대한 네트워크 데이터 안에서 내부 연결이 강한 집단을 찾아내는 데이터 분석 기술을 말한다. 하지만 관계망이 커질수록 네트워크 전체를 모두 분석해 특정 그룹을 찾아내기 어렵다. 특정 그룹을 찾아내더라도 그 그룹의 크기가 너무 크면 가치 있는 정보로 활용하기 어렵다.
연구팀은 관심 사용자를 중심으로, 원하는 범위 내에서 의미 있는 그룹을 찾는 알고리즘을 개발했다. 전체 네트워크 정보를 모두 확보하지 않아도 사용자가 정한 크기 안에서 촘촘한 연결성을 파악해 바깥 그룹과 내부 그룹을 구분한다.
연구팀은 실제 관계망 속 '친한 그룹'은 단순히 연결이 많은 관계가 아니라는 점에 주목했다. 친한 그룹은 내부적으로 오밀조밀 밀집돼 있으면서, 외부와 잘 구분되는 구조를 갖고 있다.
이를 활용해 개발한 'LSM'(Local Sketch Modularity)은 관심 사용자 주변의 로컬 정보를 활용해 주변 후보와의 관계를 차례대로 확인한다. 그렇게 집단을 넓혀 가며 특정 후보를 관계망에 넣을 때 전체 연결 구조가 더 좋아지는지 계산한다. 아닌 경우 후보에서 제외한다. 그룹을 넓혀가면서도 그룹이 불필요하게 커지지 않도록 계속해서 전체 점수를 조정한다.
하나씩 후보군을 고르는 과정에서 놓칠 수 있는 관계는 관심 사용자 주변의 작은 묶음을 함께 살펴보는 방식으로 보완했다. 혼자 있을 때는 눈에 띄지 않지만, 묶어 보면 집단적 성격이 분명하게 드러나는 후보군을 반영하기 위해서다.
실제 네트워크 데이터에 알고리즘을 적용한 결과, 기존 최고 성능으로 평가받는 기법보다 1.39배 높은 F1 점수, 최대 5.95배 높은 ARI 점수를 받았다. F1 점수는 알고리즘이 얼마나 정확한 답을 내놨는지 평가하는 지표다. ARI 점수는 데이터를 유사도에 따라 잘 분류했는지 평가하는 지표다.
연구를 이끈 김 교수는 "사용자가 관심 있는 대상 주변에서 의미 있는 관계만 빠르게 찾아내는 기술로 특정 고객군 분석, 이상 거래 탐지, 생물학 단백질 관계망 분석 등 다양한 분야에 적용할 수 있다"고 했다.
이번 연구는 김다희 UNIST 연구원이 제1저자로 참여했다. 한국연구재단의 지원을 받았다.
