[MT리포트] 차세대 AI 주도권 경쟁 - ④
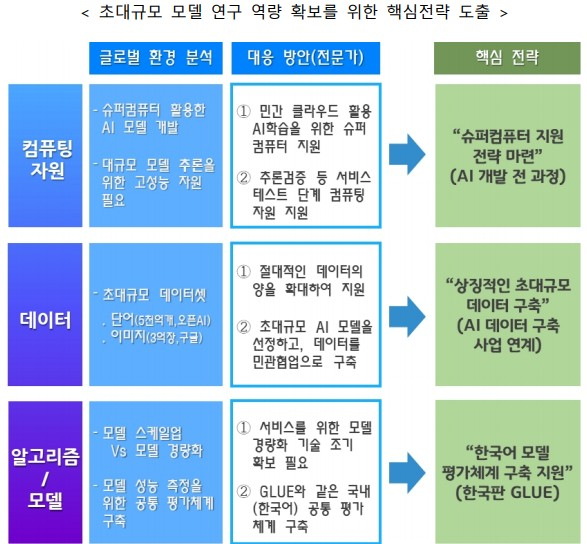
국내 기업들이 앞다퉈 '초거대 AI' 개발을 공언하고 있지만 이를 위해선 수많은 난제를 넘어야 한다. 국내 AI 연구나 인프라가 해외에 비해 뒤처진 만큼 초거대 AI 구축을 위해서는 민관의 대규모 투자와 함께 정부 차원의 연구 인프라나 제도적 지원이 시급하다는 지적이다.
전문가들은 우선 AI 학습시간 단축과 추론성능 강화를 위해 정부 차원의 슈퍼컴퓨터 지원 전략이 필요하다고 봤다. 슈퍼컴퓨터는 AI 개발을 위한 필수 인프라이지만 몇몇 대기업을 제외하곤 이를 갖추기 여의치 않다. AI 연구용 공공 슈퍼컴퓨팅 인프라를 확충해야 한다는 의미다. 아울러 영어에 비해 한국어 기반 자료가 턱없이 부족한 탓에 기본 데이터의 절대량을 늘릴 필요성도 강조됐다.
{kind=link}
장병탁 서울대 AI연구원장(컴퓨터공학부 교수)은 "인간은 아기일 때부터 '젖병'이라는 단어를 직접 만지고 느끼면서 체득하지만, AI는 주입된 텍스트를 가지고 인간과는 반대의 방향으로 학습해왔다"며 "이 때문에 AI가 상황이나 맥락을 파악하는 인간의 '상식'이 생기기 어려웠던 것"이라고 설명했다.
그러면서 "하지만 최근 영상 데이터나 웨어러블 센서 등을 통해 시각이나 촉각 등의 다양한 데이터들을 AI가 학습할 수 있게 되면서 사람처럼 학습할 수 있는 길이 열렸다"고 강조했다. 이 때문에 인간 수준의 AI를 만들기 위해선 아주 방대한 데이터가 필요하며, 사실 이는 막대한 투자를 필요로 한다는 게 그의 설명이다.
데이터 확보과정에서 정책적 지원을 요구하는 목소리도 있다. 특히 학계에서는 최근 AI 챗봇 서비스 '이루다' 사태가 데이터 규제를 강화하는 방향으로 흐를까 우려한다. 정책적 모호성이 연구 과정에서의 AI 모델의 경쟁력을 떨어뜨릴 수 있다는 것이다.

{kind=link}
고학수 한국인공지능법학회장(서울대 로스쿨 교수)은 "사실 대규모 언어모델을 만든다고 하면 아무리 비식별 처리를 해도 그 안에 개인정보가 섞여 있게 되고 이를 완벽하게 구분하는 게 현실적으로 불가능하다"며 "이 때문에 현장에서도 개발자들은 어느 정도까지가 혐오발언인지에 대해 반문한다. 여기에 규제기관이 답을 해줘야 하는 것"이라고 지적했다. 100% 완벽한 AI를 기대하지 말고 각 상황 및 특성 등 현실을 반영해 평가요소와 중요도를 정하는 '위험 기반 접근법'(Risk based watch) 등이 필요하다고도 했다.
연구인력난 역시 숙원 과제다. 산업연구원에 따르면 AI 사업 추진 기업 283곳중 53%는 AI 활용에 어려움을 겪는 이유로 '인력 문제'를 꼽았다. 차상균 서울대 데이터 사이언스 대학원장은 "초거대 AI를 만들기 위해서는 데이터 사이언스가 중요한데, 제일 힘든 것은 사람이 없다는 것"이라며 "정부와 기업의 투자가 절실하다"고 말했다.