NIA, AI 한국어·안전성 평가 데이터셋 구축
K-AI 리더보드에 'NIA 벤치마크'로 운영 예정
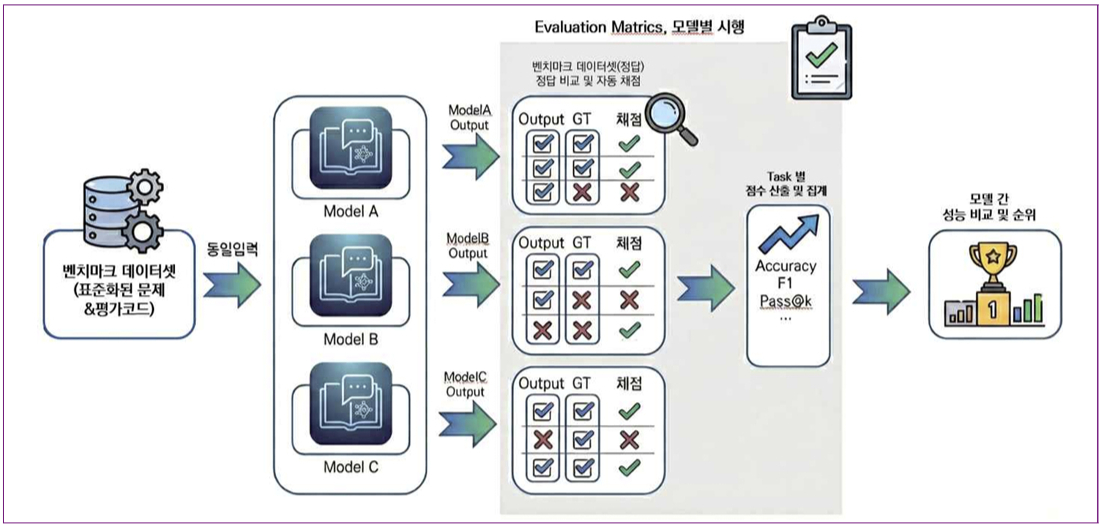
정부가 국가대표 AI 모델의 한국어 실력과 사회적 안전성을 객관적으로 검증할 수 있는 독자적인 벤치마크 구축에 나선다. AI 성능이 비약적으로 발전하면서 정교한 평가 도구의 중요성도 커진 만큼 공신력 있는 기준을 마련한다는 취지다.
23일 업계에 따르면 과학기술정보통신부와 한국지능정보사회진흥원(NIA)은 최근 'AI 모델 벤치마크 데이터셋 구축 사업'에 본격 착수했다. 벤치마크는 동일 조건에서 여러 AI 모델 성능을 정량적으로 비교·측정하는 '표준 시험지'다. 이를 위해 NIA는 올 연말까지 △한국어 △지시 이행 △사회적 안전성 등 3개 영역에서 각 1만 문항에 달하는 문답 세트(데이터셋)를 개발할 계획이다. 지난해 수학, 지식, 장문 이해
데이터셋 구축에서 범위를 확대한 것이다.
이번 벤치마크는 단순 한국어 구사를 넘어 한국 특유의 사회·문화적 맥락 이해도를 측정하는 데 도움이 될 전망이다. 예컨대 AI 모델이 맞춤법과 띄어쓰기 같은 기초 어문 규정은 물론 고어나 지역방언을 이해하고 표준어로 변환할 수 있는지 등을 점검할 수 있다. 또 AI가 이용자 지시를 충실히 수행하는지, 혐오나 차별 발언을 제한하는 안전장치가 제대로 작동하는지 등도 검증 가능하다. 정부는 국대 AI를 선발하는 '독자 AI 파운데이션 모델'(독파모) 프로젝트 평가에 데이터셋 일부를 활용할 계획이다.
과기정통부와 NIA가 운영하는 'K-AI 리더보드'에도 해당 벤치마크를 활용한다. AI의 한국어 성능을 비교·분석하는 K-AI 리더보드는 KMMLU-Pro, CLIcK 등 5개 지표로 모델 순위를 매긴다. 앞으로는 정부가 구축한 벤치마크를 추가해 평가를 다각화할 예정이다.
정부가 직접 벤치마크 구축에 나선 이유는 국내 AI 모델 경쟁이 치열해지면서 공정하고 객관적인 평가 도구 필요성이 커져서다. 그동안 국내 AI 모델 평가에 해외 벤치마크를 주로 썼으나 영미권 중심 문항으로는 한국적 특색을 제대로 반영하기 어렵다는 지적이 잇따랐다. 민간 차원에서 별도 한국어 벤치마크를 만들기도 했지만 데이터 규제와 높은 구축 비용이 걸림돌로 작용했다. 특히 텍스트를 넘어 시각·행동 정보까지 아우르는 멀티모달 벤치마크 시대엔 이같은 한계가 더욱 두드러질 전망이다.
다만 정부는 이번 벤치마크를 강제적인 인증 제도로 운영하지는 않을 방침이다. 과기정통부 관계자는 "민간 사업자들이 자율적으로 활용할 수 있는 다양한 평가 도구 중 하나로 제공할 예정"이라고 말했다.

{kind=link}